| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 유료강좌
- 포트폴리오
- 미가공
- Time
- do it c
- 마이크로소프트
- 별찍기
- SSG
- ListBox
- 도움말
- linux
- MFC
- 김성엽
- visual
- C++
- tips강좌
- MFC 예제
- MyThread
- 정보처리기사
- C
- MyTread
- 실습
- win32
- C언어
- 핵심 요약
- Tipsware
- mysql
- 충무창업큐브
- 정처기 독학
- mfc 실습
- Today
- Total
History
c 언어 온라인 무료강좌 6차시 정리 본문
해당 게시물은 김성엽 선생님의 강의를 바탕으로 만든 게시물입니다.
●2차 배열
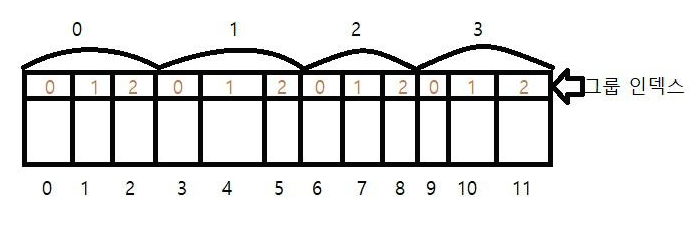
아래 그림은 1차원 배열이고 인덱스는 0부터 시작하여 하나씩 증가되는 형태이다.
그러나 이렇게 인덱스를 늘리다 보면 끝이 없고 나중에는 몇 번째 인덱스에 어떤 데이터가 들어갔는지 헷갈릴 수 도 있다. 그렇기에 데이터를 보관할 때는 그룹화를 이용하는 것이 좋다. 이제부터 그룹화를 이용해서 아래 그림을 수정해 보겠다.

아래 그림을 보면 1차원 배열과 다른 점이 있다.
1: 그룹화 되어있다.
2: 그룹화되어있는 부분의 인덱스가 3칸씩 초기화되어 증가한다.
이렇게 하면 데이터를 기억하기 편하다. 왜냐하면 7번째 인덱스의 값이 4라고 가정했을 때 그룹화시킨 2차 배열은 2번째 그룹 1번째 인덱스에 4라는 값이 있다. 이렇게 기억하면 나중에 숫자가 커졌을 때 관리와 기억이 훨씬 쉽다.
그럼 2차 배열 표기 방법을 표현해보자.
1차원 배열: 자료형 arr[n];
2차 배열: 자료형 arr[n][m];
그럼 위의 그림으로 2차원 배열을 표기해보면 arr[4][3]; 이렇게 나온다.
왜냐하면 그룹이 4개가 있고 한 그룹당 3칸의 인덱스를 부여했기 때문이다.
만약 그룹이 7이고 그룹 내 인덱스가 2면, arr[7][2]; 라고 쓰면 된다.
결론: 2차 배열은 숫자가 커질수록 데이터 관리가 용이해진다.
p.s) 2차 배열이니까 2차원적으로 생각하면 세로축이 y, 가로축이 x이다.
3개의 그룹이 있고, 그 그룹 내 3개의 인덱스가 존재한다고 하면,
0번째 그룹에 0 1 2 이렇게 표현되고, 1번째 그룹은 그 아래줄에 0 1 2 이렇게 표기된다.
그래서 세로축(그룹 번호)이(가) y이고 가로축(그룹 내 인덱스)이(가) x라는 결론이 나온다.
그래서 변수로 대입하면 arr[y][x]라는 값이 나온다.
난 arr[x][y]라고 해도 별로 상관없다고 생각한다. 이해할 수 있으면
그럼 1차원 배열과 2차 배열의 연관된 공식 하나만 알아보고 가자
arr[4][3]으로 선언된 코드가 있고
arr[2][1]=5;라는 코드가 있다. 이 이차 배열은 일차원 배열로 나타내면
arr[7]=5와 같다. 그러면 arr[2][1]와 arr[7]의 위치는 어떻게 같은지 알 수 있을까?
공식: y*x축 항목 수+x
이 공식을 이용하면 된다. 한번 대입해보자.
이차 배열에서 y축은 2이고 x축은 1이다.
2* x축 항목 수+1=7
x축 항목 수는 =3
x축 항목 수는 {0, 1, 2} 3개가 맞다.
그럼 반대로 생각해보자. arr[7]이라는 것을 알고 있는데 이차 배열 어느 인덱스에 들어가는지 알 수 있을까?
마찬가지로 arr [4][3]이라는 코드가 있다. 이 코드에서 x축 항목은 3이었다.
이제 arr[7]에서의 7을 3으로 몫과 나머지로 나눈다.
그러면 몫은 2 나머지는 1이 나오고
몫은 y축 나머지는 x축에 대입하면 끝이다.
그러면 arr[2][1]이 나온다.
●표기법 혼용
포인터를 사용할 때 *(p+2)=3; 이렇게 사용한다. 그때 (*) 포인터 이 기호는 연산자 우선순위가 낮기 때문에
괄호가 많이 나와서 헷갈릴 때가 많다. 그래서 괄호를 줄이기 위해
p[2]=3; 이렇게 사용이 가능하다.
마찬가지로 반대로 쓰는 것도 가능하다.
char data[5];라고 했을 때
data[2]=3; 이 코드는
*(data+2)=3; 이렇게 쓰는 것이 가능하다.
이제 이 data 배열을 그림으로 표시해보자.

위의 그림처럼 data의 그림이 있다. 이 그림에서 설명했듯이 data[0]번째는 data의 시작 주소이고, 이 주소의 표기는
&data[0]으로 표기가 가능하다.
또한
&*(data+0)으로도 표기가 가능하다.
+ &*는 붙어있으면 생략 가능 data+0이라고 해도 되지만 +0도 생략하면 data라고 적는다.
그러면 data라고 적으면 배열의 0번째를 가리키는 코드이다.
둘 다 data의 0번째 시작 주소를 가리키는 코드이다.
+추가) &data[3] 이 코드와 data+3은 같은 코드이다.
반대로
data[0]는 data의 0번째 안에 있는 데이터를 참조하는 코드이다.
또한
*(data+0)도 같은 표기이다.
둘 다 data의 0번째 데이터를 참조하는 코드이다.
포인터를 배열로 바꾸는 이유는 코드를 단순화시켜서 이해를 좀 더 편하게 하려고 바꾼다.
확실히 그렇다. 왜냐하면 *(data+3) 이렇게 사용하는 것보다 data[3] 이렇게 쓰는 게 더 직관적이고 이해하기 편하다.
그러면
배열을 포인터로 바꾸는 이유는 뭘까?
답은 형 변환을 해서 원하는 만큼 사용하려고 쓴다.
예를 들어 예전에 공부했던 주소 연산을 떠올리면 이해하기 좀 더 편할 것이다.
int n;
n=0x12345678;
아래 그림처럼 n은 4byte 배열이 있고 순차적으로 78/56/34/12 이렇게 데이터가 들어간다. 그리고 빨간색으로 표시한 범위만큼 77/33의 데이터를 입력하고 싶으면

아래 코드처럼 입력하면 된다.
(short)n=0x3377;
or
*(short*)&n=0x3377; //일반 변수여서 포인터 사용 x 그래서 &를 사용해서 포인터를 사용 가능하게 만들어 준다.
이처럼 배열도 똑같이 바꿀 수 있다.
예를 들어 아래와 같은 코드가 있다.
int data[3];
그러면 그림은 아래와 같다.

3개의 방이 생겼고 그 방은 각각 4등분이 되어있을 것이다. 이때 아래 그림처럼 색칠되어있는 부분에만 데이터를 대입하고 싶을 때는

아래 코드처럼 작성하면 된다.
(short)data[2]=3;
그러나 아래 그림처럼 대입하고 싶으면 어떻게 해야 하는가?

이렇게 바꾸고 싶으면 바로 위에 작성했던 배열 표현으로는 바꿀 수 있는 방법이 없다.
그러나 이때 포인터 표기법으로 바꾸면 내가 원하는 곳에 데이터를 대입할 수 있다.
(short)data[2]
=> *(data+2)
=> *((char*)(data+2)+1)
=>*(short*)((char*)(data+2)+1)
위와 같은 과정을 거치면 내가 색칠한 공간에 값을 대입할 수 있다. 우선 data [2]를 포인터 표기법으로 바꾸면 *(data+2)라는 값이 나오고 1칸을 앞으로 가야 하기 때문에 1byte인 char형으로 형 변환을 해준다. 그러면 *((char*)(data+2)+1) 이렇게 코드가 작성된다. 왜 +1이냐면 data는 int 형이기 때문에 +2가 되면 2byte가 아니라 8byte가 늘어난다. 그래서 +1을 해준다. 그리고 마지막으로 short형으로 형 변환시켜서 2byte의 값을 대입한다.
물론 아래 코드처럼 해도 상관없다.
(short)data[2]
=> *(data+2)
=> *((char*)(data+9)
=>*(short*)((char*)(data+9)
자 그럼 한 문제 더 풀어보자
아래 그림처럼 데이터를 대입하려면 어떻게 해야 하는가?

이 코드 역시 배열 형식으로 코드를 작성하기에는 무리가 있기에 포인터 표기법으로 작성해야 한다.
data[1]
=>*((short*)(data+1)+1)
위의 코드처럼 작성하면 내가 원하는 곳에 데이터가 들어갈 것이다. 왜냐하면 현재 색칠된 데이터의 위치는 배열로 data[1]의 위치이다. 이 표기법을 포인터로 바꾸면 *(data+1) 이렇게 바뀌고 이 번지는 4번지를 가르킨다. 그리고 short 형식으로 형 변환을 하고 +1을 하면 2byte가 뒤로 밀리기 때문에 내가 색칠한 부분이 시작 부분이 될 수 있다.
또 다른 코드를 보자.
data[1]
=>*((short*)(char*)(data+6)
이렇게 해도 정답이다. data의 0번지부터 +6을 하면 내가 색칠한 부분이 시작 부분이 되기 때문에 short로 형 변환하면 원하는 답이 나온다.
마지막으로 이런 것도 가능하다.
data[1]
=>*((short*)(data+2)-1)
*(data+2) 즉 data[2]번지의 시작 주소로 옮겨지고 short의 크기만큼 뺄 수 도있다. 그러면 위에 답들과 같은 결괏값이 나온다.
● 2차 포인터 가기 전 예열
지금부터 쓴 것들은 전부 이해하고 외워야 한다. 수기로 10번 이상은 쓸 것
1
만약 아래와 같은 코드가 있다.
char temp [3][4];
temp [1][2]=5;
이 표현은 temp의 (2,1)의 좌표에 5를 대입하라는 뜻이다. 이제부터 같은 뜻이지만 3가지의 서로 다른 표현을 써보겠다.
2
temp [1][2]에서 (temp [1])[2] 이 괄호는 생략됐다고 볼 수 있다. 그럼 괄호 안에 있는 값을 포인터 표기법으로 바꿔보자.
(temp [1])[2]=5;
=>(*(temp+1))[2]=5;
위의 코드와 같이 나온다. 그러나 *(temp+1)[2] 이렇게 사용하면 안 된다. 왜냐하면 []의 연산자 순위가 *보다 높기 때문이다.
ps) 방금 *(temp+1)[2]은 잘못된 표현인데 컴파일러 상에서는 잘못된 표현이 아니라고 해석한다. 그래서 에러가 나지는 않지만 원하는 결괏값이 절대 나올 수 없다. 그러면 이 값은 어디에 저장되는지 알아보자.

위의 그림처럼 컴파일러가 인식하는 연산자 우선순위이다. 괄호 안의 덧셈이 먼저 실행되고 []가 두 번째, 포인터가 마지막 순서이다.
*((temp+1)[2])과 같은 뜻이다.
그리고 []는 포인터 표기법으로 변형이 가능하므로
*(*((temp+1)+2))라는 값이 나온다.
이 값은 *(*((temp+3))과 같다.
이제 배열 표기법으로 바꾸면 *tmep [3]=5가 되고 이 값은
*(temp [3]+0)과 같기 때문에 temp [3][0]=5라고 표기할 수 있다.
순서를 정리하면 아래 코드처럼 된다.
*(temp+1)[2]
=>*((temp+1)[2])
=>*(*((temp+1)+2))
=>*(*((temp+3))
=> *tmep[3]
=>*(temp [3]+0)
=> temp [3][0]
3(치환 문)
2번과 마찬가지로 (temp [1])[2]=5;라는 코드가 있다. 그러나 2번과는 다르게 (temp [1])를A로 치환하여 작성해보겠다.
그러면 A [2]=5; 가 되고 포인터 표기법으로 바꾸면 *(A+2)=5;
치환을 풀면 *(temp [1]+2)=5;라고 쓸 수 있다.
정리하자면
temp [1][2]=5;
=>(temp [1])[2]=5;
=>(temp [1])를A로 치환
=> A[2]=5;
=>*(A+2)=5;
=>*(temp [1]+2)=5;
이렇게 쓰면 복잡한 코드도 좀 더 직관적으로 볼 수 있어서 보기 편하다.
4
3번째 마지막에 있는 코드를 한 번 더 포인터 표기법으로 변형하는 것이다.
*(temp [1]+2)=5;
=>*(*(temp+1)+2)=5;
+추가) 1 포인터 배열이란?
int *p[3]; <- 이 코드는 무슨 뜻일까?
이 뜻은 p[3]의 배열 각각이 int *라는 뜻이다.
쉽게 설명해서 우리가 배열을 사용하는 이유는 int a1, a2, a3, a4, a5, a6, a7, a8 이러한 막일보다는
int arr[8]; 이렇게 쓰면 훤씬 간편하다.
마찬가지로 좀 더 단순하게 하기 위해 포인터도 여러 번 사용하는 상황이 있을 수 있으니까
배열처럼 한 번에 묶어쓰자 라고 하는 게 포인터 배열(포인터를 항목으로 가지는 배열)이다.
+추가) 2 포인터 배열을 왜 쓸까?
int data[3][5]; 라는 코드가 있는데 이 3과 5는 상수값(고정된 값)이다.
3과 5 둘 중 하나라도 바꾸면 소스 전체를 바꾸고 다시 빌드를 해야 한다. 왜냐하면 스택 프레임에 직접적인 영향을 미치기 때문이다.
그렇기 때문에 이 둘 중 1개라도 변수 처리할 수 있게 하기 위해 사용하는 것이 포인터 배열이다.
원래는 2개 다 변수 처리하는 것이 좋다. 그러나 사람들 실력이 안돼서 타협하는 것이 1개만 바꾸는 것이다.

위의 그림은 data [3][5]의 모양이다. 그러나 이 코드는 아까도 말했듯이 고정된 값이기 때문에 코드를 바꿀 일이 있을 시 곤란할 수 있다. 그럼 포인터 배열을 사용해서 만들어보자.
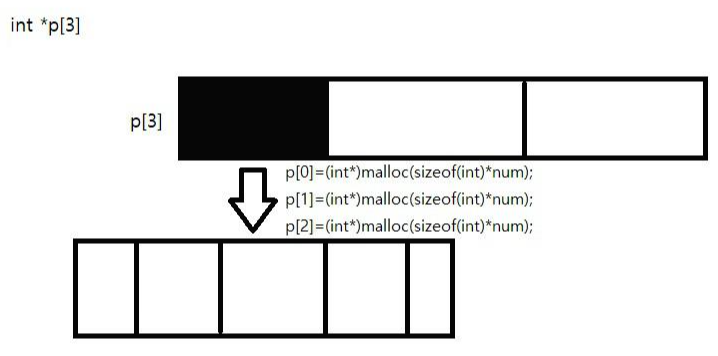
먼저 int*p[3];이라는 코드가 있고 이 코드로 이차원 배열의 모양을 만들려면 아래와 같은 코드를 작성해야 한다.
p[0]=(int*)malloc(sizeof(int)*5);
p[1]=(int*)malloc(sizeof(int)*5);
p[2]=(int*)malloc(sizeof(int)*5);
이렇게 코드를 작성하면 아래 그림과 같다.

이렇게 되면 [상수][상수]가 아닌 [상수][변수]로 바꿀 수 있기 때문에 좀 더 프로그램 수정에 용이할 수 있다.
아래 그림처럼 *5를 *num으로 바꿀 수 있다는 소리이다. 그러면 scanf함수로 사용자의 입력을 받아서 수정 가능
그럼 다른 방식으로 int data[3][5]를 표현해보겠다.
int *p;
p=(int*)malloc(sizeof(int)*3*5);
=> 변수화
p=(int*)malloc(sizeof(int)* x * y);
위의 코드처럼 작성하면 값을 참조할 때 이차 배열에서 배웠던 공식을 쓰면 된다.
*(p+y+x의 항목 개수+x)
이렇게 구성하면 이차 개념을 사용할 필요가 없다.
또 다른 방법은 int[*p][5]; 이렇게 선언하는 것이다. 만약 data[2][1]에 데이터를 대입한다고 하면
방금 쓴 공식을 대입하면 된다.
그러면 다른 방법으로 [2][1]에 대입한다고 하면 (*(p+2))[1]=5; 이렇게 적으면 된다. 이 코드는 p[2][1]로 바꿀 수 있다.
'Tipslab 강좌 복습 > 김성엽 선생님 c 강의 복습' 카테고리의 다른 글
| c 언어 온라인 무료강좌 8차시 정리 (0) | 2021.02.03 |
|---|---|
| c 언어 온라인 무료강좌 7차시 정리 (0) | 2021.01.31 |
| c 언어 온라인 무료강좌 5차시 정리 (0) | 2021.01.21 |
| c 언어 온라인 무료강좌 4-2차시 정리 (0) | 2021.01.20 |
| c 언어 온라인 무료강좌 4-1차시 정리 (0) | 2021.01.19 |



